
About Me
 lead you to my latest work!
lead you to my latest work!Hello! I am Zhenglin Cheng, a second-year Ph.D. student of ![]() LINs lab, Westlake University (through joint program with ZJU), advised by Prof. Tao LIN.
Before that, I received my bachelor’s degree in Software Engineering from Zhejiang University (ZJU).
LINs lab, Westlake University (through joint program with ZJU), advised by Prof. Tao LIN.
Before that, I received my bachelor’s degree in Software Engineering from Zhejiang University (ZJU).
📄 Find my CV here (Jan 2026 Update).
News
- 2026/01, 🥳 TwinFlow is accepted to ICLR’26, see you in Rio de Janeiro, Brazil 🇧🇷 !
- 2025/12, 🚀 We release TwinFlow, a simple and effective framework for one-step generation!
- 2025/01, 🥳 Dynamic Mixture of Experts (DynMoE) is accepted to ICLR’25, see you in Singapore 🇸🇬 !
Research Interests
My long-term research goal is to build efficient multimodal agents that can understand the physical world, reason on real-world problems, and generate novel ideas, which could also learn from experience and evolve themselves in the constantly changing environment.
Looking at the present, I put my focus on:
- Unified multimodal models: how to effectively and efficiently combine diffusion and autoregressive paradigm?
- Few-step generation: how can we effectively train/distill continuous diffusion generators into 1-NFE ones—and can the same be done for dLLMs?
Publications/Manuscripts (* denotes equal contribution)
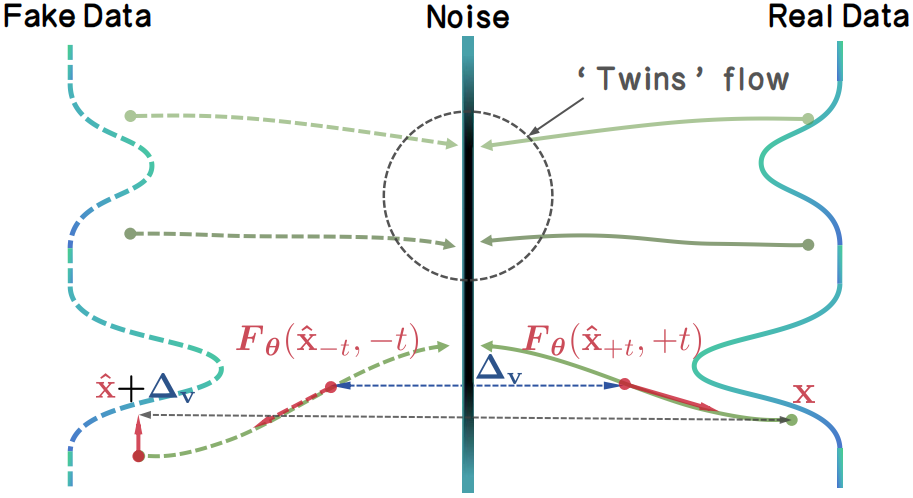

📖 TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows
Zhenglin Cheng*, Peng Sun*, Jianguo Li, Tao Lin
![]()

👉 TwinFlow tames large-scale few-step training through self-adversarial flows, eliminating the need for any auxiliary networks (discriminators, teachers, fake scores) by one-model design. This scalable approach transforms Qwen-Image-20B into a high-quality few-step generator.
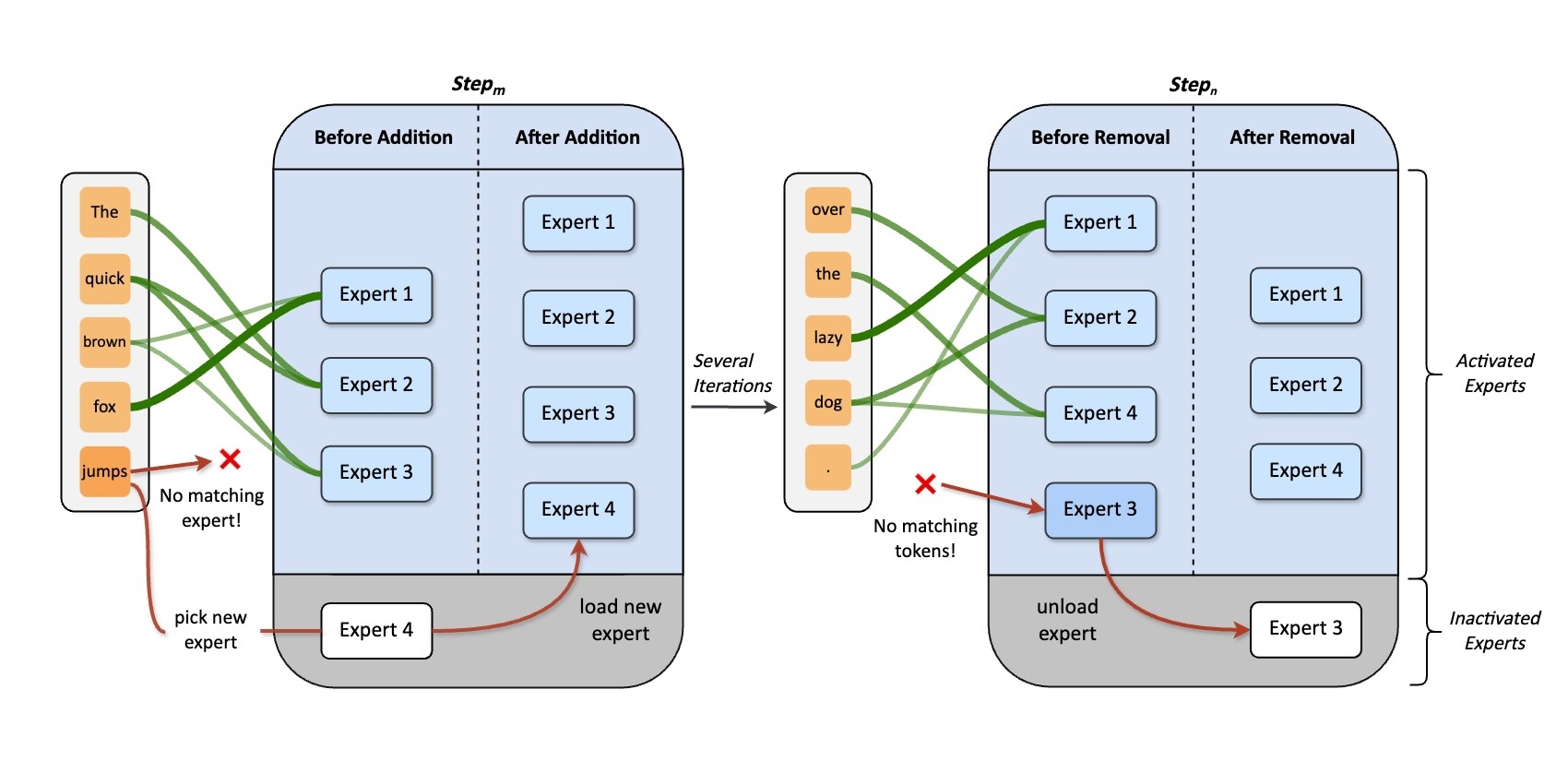
📖 Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Yongxin Guo*, Zhenglin Cheng*, Xiaoying Tang, Zhaopeng Tu, Tao Lin

👉 DynMoE frees the burden of pivotal hyper-parameter selection for MoE training by enabling each token to activate different number of experts, and adjusting the number of experts automatically, acheiving stronger sparsity well maintaining performance.
Experiences
- 2025/07 - Present, inclusionAI, Ant Group (Tech Leader: Dr. Jianguo Li).
Academic Services
- Conference Reviewer: ICLR, ICML.
Educations
- 2024/09 - 2029/06, Westlake University, College of Engineering.
- 2020/09 - 2024/06, Zhejiang University, College of Computer Science and Technology.