1. Terms & Concepts¶
约 957 个字 预计阅读时间 3 分钟
Message & Batch | 消息 & 批次¶
Kafka 的数据单元被称为 消息(Message),类似于数据库中的一行记录。消息由字节数组组成,可以包含任何内容。Kafka 没有对消息的格式和内容做任何限制,只是把它们当作字节数组来处理。
消息有一个可选的键(Key)。对键的哈希值取模可以用来对消息进行分区,这样可以保证具有相同键的消息总是被写到相同的分区上。
为了提高效率,消息被分批次写入 Kafka。批次(Batch) 就是一组消息,这些消息属于同一个主题(Topic)和分区(Partition)。
Schema | 模式¶
为了更好地定义消息使得其易于理解,Kafka 支持消息的 模式(Schema)。
模式是一个结构化的数据格式,它定义了消息的字段名称、类型和顺序。模式可以是 JSON、XML、Avro、Thrift、Protocol Buffers 等格式。
Topic & Partition | 主题 & 分区¶
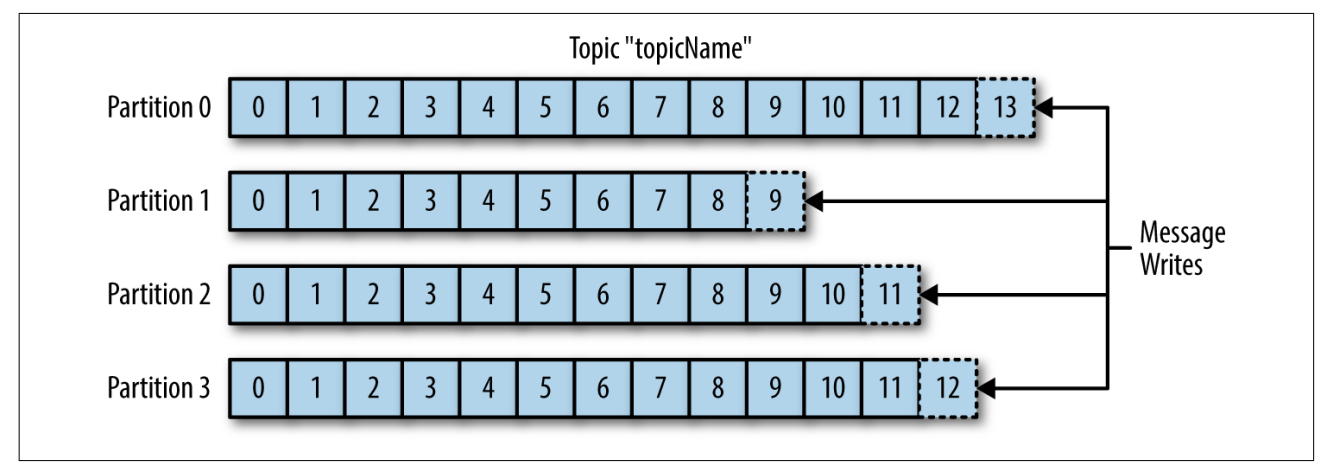
Kafka 的消息通过 主题(Topic) 进行分类。一个 Topic 可以被分为若干个 分区(Partition)。消息以 FIFO 的顺序写入分区。
由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。分区可以分布在不同的服务器上,也就是说一个主题可以横跨多个服务器。
Producer & Consumer | 生产者 & 消费者¶
生产者(Producer) 创建消息。一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,但也可以通过键和分区器(Partitioner)来写入到特定的分区。分区器为键生成一个哈希值,并将其映射到指定的分区上。生产者也可以使用自定义的分区器。
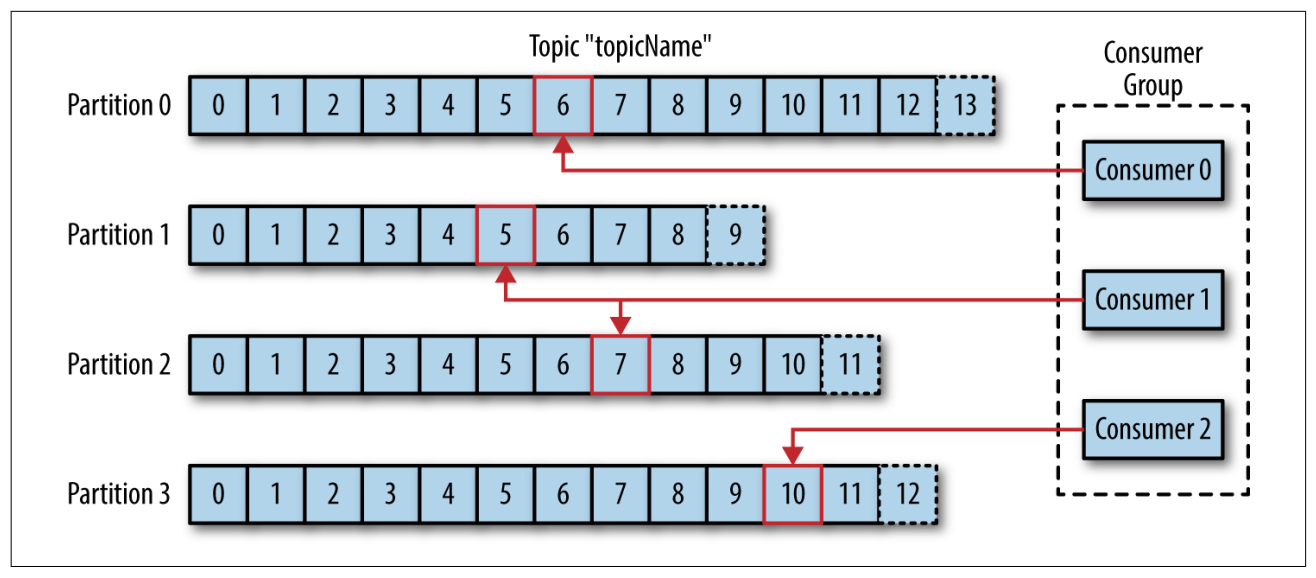
消费者(Consumer) 读取消息。消费者订阅一个或多个主题,并按照消息生成的顺序读取。消费者通过检查消息的偏移量(Offset)来区分已经读取过的消息。偏移量是一种元数据,它是一个递增的整数。在创建消息时,Kafka 为每条消息生成一个 在分区里唯一 的偏移量。
多个消费者可以组成一个 消费者组(Consumer Group)。群组保证每个分区只能被一个消费者使用。
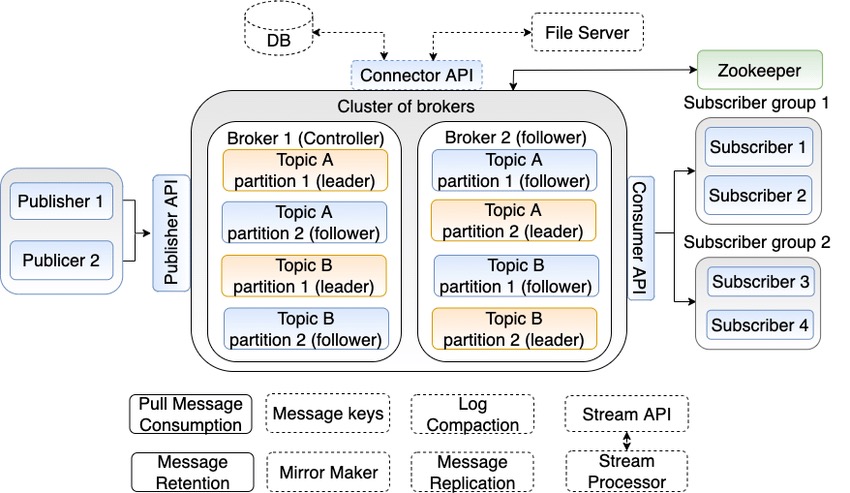
Broker & Cluster | 代理 & 集群¶
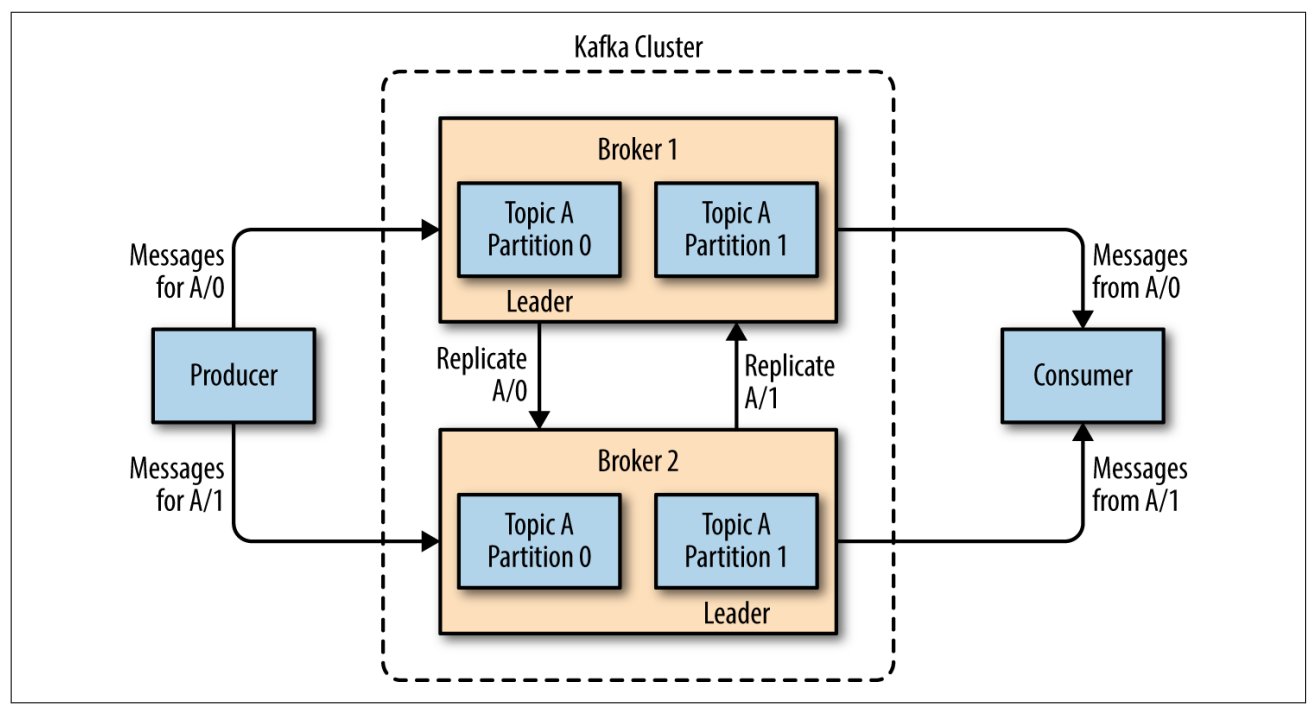
Kafka 集群由多个服务器组成,这些服务器被称为 代理(Broker)。代理保存消息的副本,并处理生产者和消费者的请求。每个代理都保存了一部分主题的分区副本,因此一个主题的所有分区可以分布在整个集群上。
代理是 集群(Cluster) 的组成部分。每个集群都有一个代理充当集群控制器(Cluster Controller),控制器负责管理工作,包括将分区分配给代理和监控代理。
每个分区都可以分配到多个代理上,其中一个代理成为分区的首领(Leader),其他的代理为跟随者(Follower)。这种复制机制(Replica)为分区提供了消息冗余,如果首领宕机,其他代理可以接管领导权。
保留消息(Retention)是 Kafka 的一个重要特性。代理的默认保留策略是要么保留一段时间(比如 7 天),要么保留到消息达到一定大小的字节数(比如 1GB)。当消息数量达到这些上限时,旧消息就会过期并被删除。
到目前为止,我们已经介绍了 Kafka 的所有基本概念,可以给出一张 Kafka 的整体架构图。